
S* stands for Stream, what were you expecting? Yes, there is an interesting bug in Redis Stream and I want to talk about it.
A disclaimer before we start. This is not a rant. Software has bugs; we are humans after all (in a world where AIs still make worse mistakes, this is a bit awkward to say). This was just interesting enough to talk about. As a matter of fact, while working on this one, I realized we have an issue in our implementation as well.
This is interesting to me because the spec is really well-written. It is so detailed that it must have been written after the implementation. Such a detailed spec cannot be written before the implementation. At least, this is true for me. I need to write most of the code to create a good design/spec/doc. So, this behavior must have broken in Redis at some point. I will not dig into the details of where it broke; our friendly rivals at RedisLabs can do that, I think.
This blog will be in four sections for your convenience if you want to skip some of it.
- Use Case: Why are we using Redis Stream XINFO to get lag?
- Story: How did we realize that there is a bug in the original Redis as well?
- Specification: Description of how stream group lag is defined.
- Bug: Redis bug as of version 7.2.4, example runs, outputs, and their descriptions.
Use Case
At Upstash, we have several products. One is a custom Redis implementation, and another is QStash, which is an HTTP-based messaging solution.
Recently, we added ordered-delivery support to QStash. Now, you can use QStash as a queue to push tasks, and it will call your endpoint one by one.
QStash uses our Redis implementation to store all the necessary state. It's a perfect dogfooding case. We rely on our own product for another offering, catching some interesting bugs that can only occur in production.
For the new ordered-delivery support, we decided to use Redis Streams (our own home-baked implementation of Streams—phew, we dodged a lawsuit there). As part of the feature, it was really convenient to provide the number of messages in the queue that are not yet delivered. This is where the lag field of XINFO GROUPS comes in, and that is where things become interesting.
Story
In QStash, you can retrieve your queue and check the lag with the following API. One of our careful users reported that this lag value is not correct. QStash lag and Redis Stream lag are not the same. In the initial release of the queue, we provided the stream lag as it is. This is on us; we should have been more careful. Let me try to show the difference.
A stream is a series of items with incremental IDs. There can be multiple consumer groups consuming from this stream. Each consumer group consumes the same items in the stream and keeps track of its own delivered and pending items.
The definition of stream lag is the number of entries in the stream that are still waiting to be delivered to the group's consumers.
So, for the following example, the lag is 3.
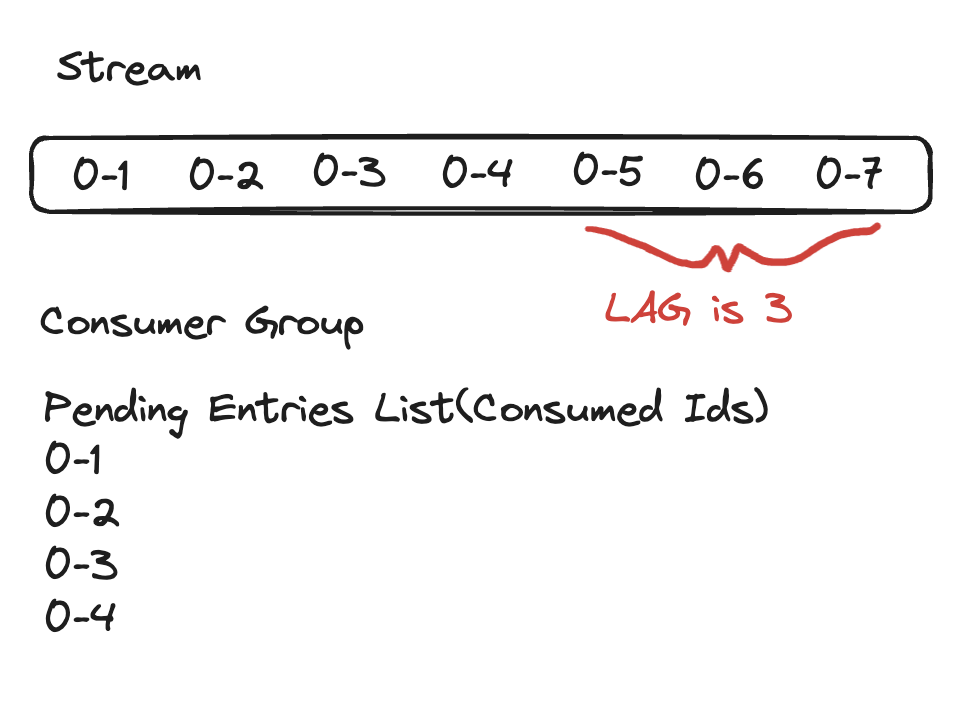
For QStash, the definition of lag is the number of unprocessed messages that exist in the queue. The picture is a bit more complicated. We consume an item from the consumer group and call the user's endpoint. Only when it is successfully delivered do we call XACK. On the stream side, when an item is read, it is put in a pending entries list. When acknowledged, it is removed from the list. Here is an example snapshot of QStash:
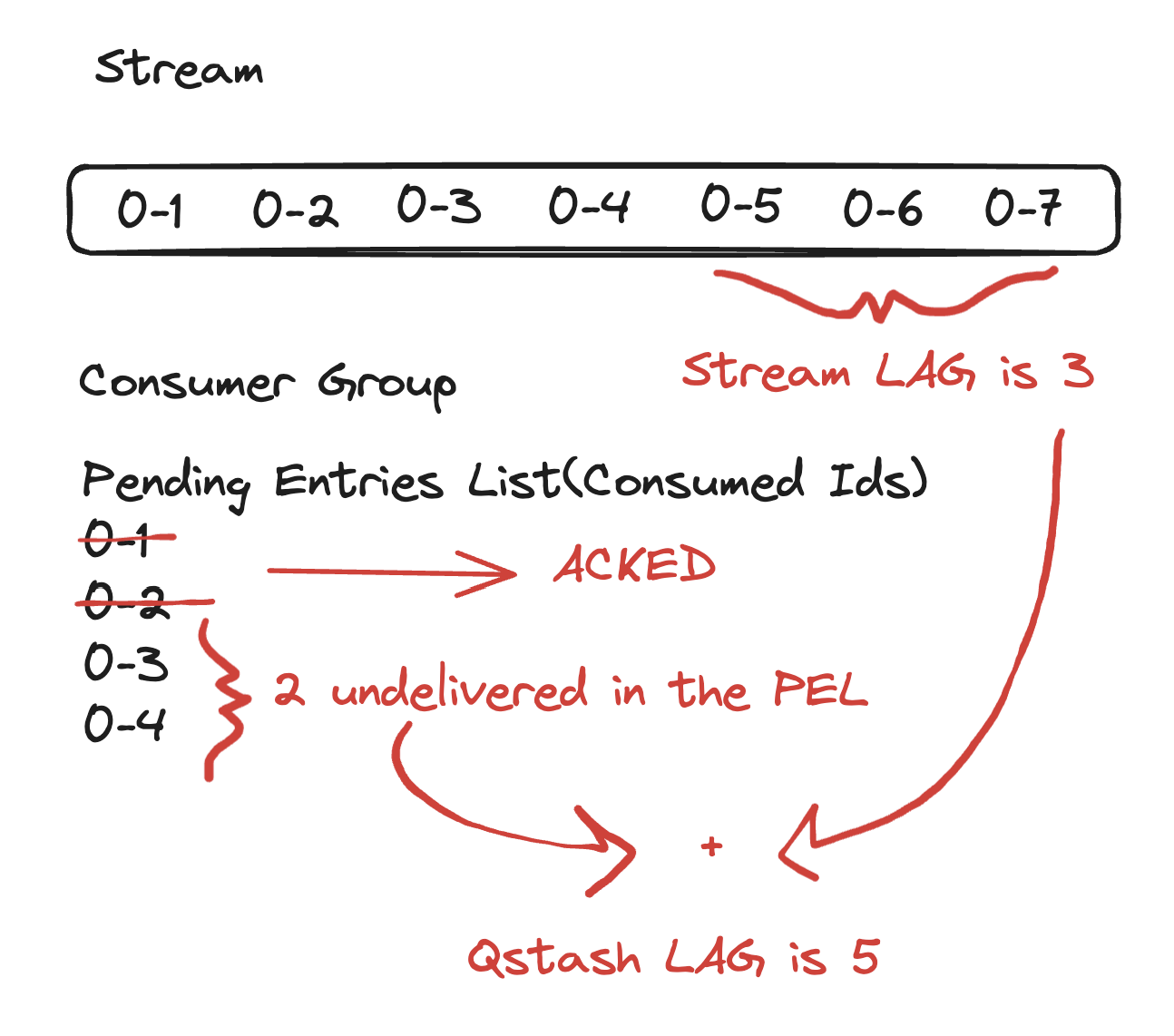
To simplify:
Queue Lag = Stream Lag + Number of Entries in the PEL.
So far, so good. The implementation of this fix is really simple. The problem arose when we tried to test the new code, mostly because this time we tested more edge cases.
miniredis
We were using miniredis, a Pure Go Redis server for Go unit tests. - Did I mention that we implemented the Redis spec and QStash in Go? - This library is perfect for QStash because we don't need to spin up Upstash Redis clusters to test QStash. The first small issue was that lag is not yet implemented in miniredis. It is a non-profit project with a single maintainer, so it is acceptable. As a responsible open-source contributor, I decided to add the missing feature and contribute back to open-source with a pull request
But there was a problem. The Redis spec and the original Redis do not behave the same. Knowing I would not like the answer, I asked the question to the maintainer (alicebob).
- Q: Which one is your preference, Redis implementation or Redis spec for miniredis?
- A: Redis, 100% :)
Totally expected; the purpose of miniredis is to mimic Redis. They need to behave the same even if the implementation is buggy. Just to relieve the stress, as this turns out to be quite a rabbit hole, I wrote a love letter ❤️ to alicebob.
Enough of the story and romance. Let's talk about the specification and the bug.
Specification
In this part, I will try to convince you why our implementation is correct. Please reach out to us on Discord if you think I am missing anything.
We will focus on two pages of the Redis spec.
entries-added: the count of all entries added to the stream during its lifetime.
This seems pretty clear, with one important detail. If we delete something from the stream, this field is not decremented. It only grows.
entries-read: the logical "read counter" of the last entry delivered to the group's consumers lag: the number of entries in the stream that are still waiting to be delivered to the group's consumers, or a NULL when that number can't be determined.
The lag of a given consumer group is the number of entries in the range between the group's entries_read and the stream's entries_added. Put differently, it is the number of entries that are yet to be delivered to the group's consumers.
Entries-read is a bit difficult to understand, but here is another description of it:
The counter attempts to reflect the number of entries that the group should have read to get to its current last-delivered-id. The entries_read counter is accurate only in a perfect world, where a consumer group starts at the stream's first entry and processes all of its entries (i.e., no entries deleted before processing).
But the world is not perfect, as described in the doc. So there are some cases where entries-read is not valid.
There are two special cases in which this mechanism is unable to report the lag:
- A consumer group is created or set with an arbitrary last delivered ID (the XGROUP CREATE and XGROUP SETID commands, respectively). An arbitrary ID is any ID that isn't the ID of the stream's first entry, its last entry, or the zero ("0-0") ID.
- One or more entries between the group's last-delivered-id and the stream's last-generated-id were deleted (with XDEL or a trimming operation). In both cases, the group's read counter is considered invalid, and the returned value is set to NULL to signal that the lag isn't currently available.
It is a bit hard to understand at first. But when you actually think about it —in my case, I had to because I have implemented all this for Upstash in Go— the documentation is reasonable. Reasonable because this is the best way to present a useful number without iterating the whole structure every time. Not perfect but a good middle ground: efficient and useful.
If the spec is not clear to you at this point, no worries. I will try to get into more detail when describing the bug with an example.
Bug
I will use the same commands as an example that I shared in the bug report on the Redis repo.
127.0.0.1:6379> XGROUP CREATE planets processing $ MKSTREAM
127.0.0.1:6379> XADD planets 0-1 name Mercury
127.0.0.1:6379> XADD planets 0-2 name Venus
127.0.0.1:6379> XREADGROUP GROUP processing alice STREAMS planets >
127.0.0.1:6379> XADD planets 0-3 name Earth
127.0.0.1:6379> XADD planets 0-4 name Jupiter
After all these commands, the state should look like the following, and Redis reports it correctly so far.

Then, we delete some of the already read items.
127.0.0.1:6379> XDEL planets 0-1
127.0.0.1:6379> XDEL planets 0-2
Redis still reports the state correctly. But I want to pause here a bit to clarify what entries-read is.
First of all, entries-read is still valid and set to 2. Lag is still reported as 2. According to this definition, it feels a bit off at this point.
The counter attempts to reflect the number of entries that the group should have read to get to its current last-delivered-id.
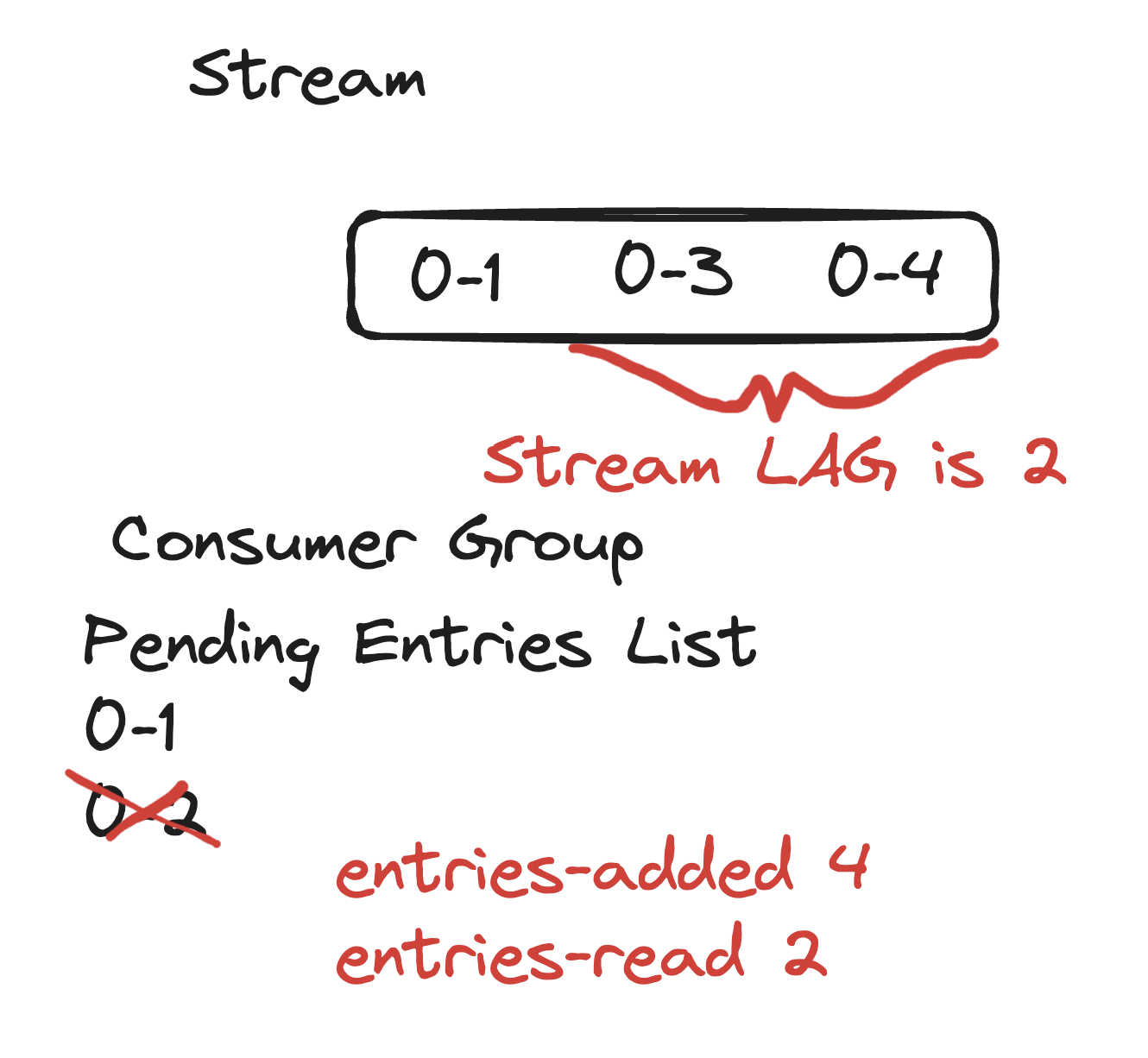
If we look at the stream after the deletion, for the group to come to 0-2, it should read 0 item, not 2. But we are still saying it is valid. If we check the lag calculation, it still checks out.
entries-added(4) - entries-read(2) = lag(2)
In terms of lag calculation, it is still valid. Hence the documentation clearly mentions that it is invalid when one or more entries between the group's last-delivered-id and the stream's last-generated-id were deleted.
So let's delete 0-3 and see what happens.
127.0.0.1:6379> XDEL planets 0-3

If you check the picture above, it is clear to us the lag is 1. But it is not efficient to come up with this anymore. We need to either traverse the stream or keep more state in memory to bookkeep what is going on. And the lag calculation does not check out anymore.
entries-added(4) - entries-read(2) != lag(1)
Here is the bug: according to the spec, XINFO GROUPS planets should report lag as NULL, but Redis still reports it as 2.
127.0.0.1:6379> XINFO GROUPS planets
1) 1) "name"
2) "processing"
3) "consumers"
4) (integer) 1
5) "pending"
6) (integer) 2
7) "last-delivered-id"
8) "0-2"
9) "entries-read"
10) (integer) 2
11) "lag"
12) (integer) 2
There is another probably related bug as well. If you continue to read the group until the end, the lag should be zero, right? Even the Redis spec mentions it.
Once the consumer group delivers the last message in the stream to its members, it will be set with the correct logical read counter, and tracking its lag can be resumed.
Let's try and see what happens.
127.0.0.1:6379> XREADGROUP GROUP processing alice STREAMS planets >
127.0.0.1:6379> XINFO GROUPS planets
1) 1) "name"
2) "processing"
3) "consumers"
4) (integer) 1
5) "pending"
6) (integer) 3
7) "last-delivered-id"
8) "0-4"
9) "entries-read"
10) (integer) 3
11) "lag"
12) (integer) 1
Wait, what? Ok. Entries-read is 3, I guess. I mean, we read 0-1, 0-2, and 0-4 so far. But the lag should have been 0, right?
Let's try to analyze the latest state:

According to both the spec and the latest state, the lag should be 0. It is a useful value only when it is 0. If every time we delete or, worse, trim something, it starts to diverge, we cannot rely on it anymore.
Our solution was to reset the entries-read to entries-added. We relied on the logical definition of entries-read being a logical counter rather than an exact one.
If you read this far, thanks for your attention. We will continue to do our best to deliver the best experience for our services. Please join us on Discord and share your thoughts if you see anything wrong or see room for improvement.
UPDATE: A quick-fix came from the redis team here