Why a workflow might fail
- A step in your workflow throws a database error that causes your code to fail at runtime.
- QStash calls your workflow URL, but the URL is not reachable - for example, because of a temporary outage of your deployment platform.
- A single step takes longer than your platform’s function execution limit.
failureFunction or a failureUrl on the serve method of your workflow.
These options allow you to define custom logic or an external endpoint that will be triggered when a failure occurs.
Using a failureFunction (recommended)
The serve function you use to create a workflow endpoint accepts a failureFunction parameter - an easy way to gracefully handle errors (i.e. logging them to Sentry) or your custom handling logic.
failureFunction too. Otherwise, anyone can invoke your failure function. Read more here: securing your workflow endpoint.
In @upstash/workflow, the failureFunction can optionally return a string value that will be displayed in the UI (coming soon) and included in the workflow logs. This is useful for providing custom error messages, debugging information, or tracking specific failure conditions.
Using a failureUrl
Instead of using the built-in failure function, you can define a separate failure callback URL.
Unlike the failure function, which only works when your application is running, the failure URL allows you to handle errors even if your application is completely down.
If the URL is a different service other than your application, it will be reachable in these cases.
By pointing the failure URL to an external service (not hosted within your main application), you ensure that it remains accessible even when your primary app is unavailable.
JavaScript
JavaScript
verifySignature allows to verify the signature of request, which is signed by Upstash using your signing keys.
If you don’t want to verify the signature, you can remove QSTASH_CURRENT_SIGNING_KEY and QSTASH_NEXT_SIGNING_KEY environment variables and remove verifySignature function.
Manually Handling Failed Workflow Runs
When a workflow run fails and is moved to the Dead Letter Queue (DLQ), you have several options to handle it manually via the REST API:Resume
- What it does: Continues a failed workflow run from exactly where it failed, preserving all successful step results.
- When to use: Use this if you want to retry only the failed/pending steps without re-executing the entire workflow.
Restart
- What it does: Starts the failed workflow run over from the beginning, discarding all previous step results.
- When to use: Use this if you want a clean execution, or if the failure may have been caused by a corrupted state that requires a fresh start.
Callback
- What it does: Reruns the failure callback for a workflow run, in case the original failure callback was not delivered or failed.
- When to use: Use this to ensure your system is notified of workflow failures, even if the original callback attempt did not succeed.
Debugging failed runs
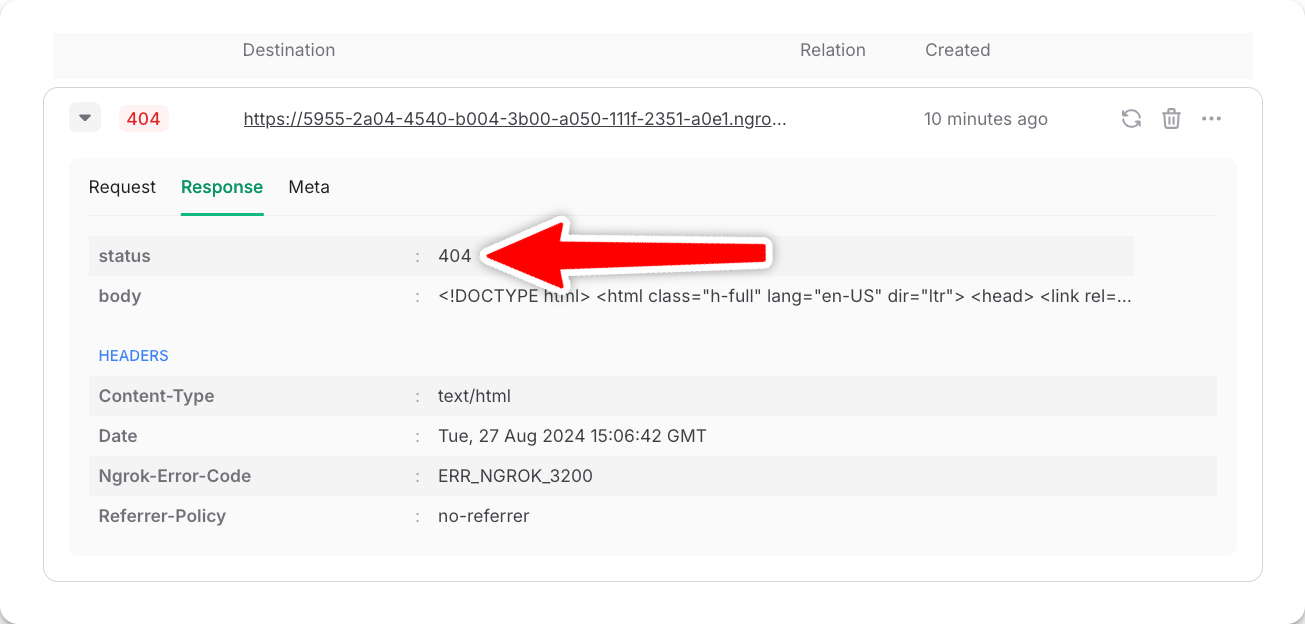
In your DLQ, filter messages via theWorkflow URL or Workflow Run ID to search for a particular failure. We include all request and response headers and bodies to simplify debugging failed runs.
For example, let’s debug the following failed run. Judging by the status code 404, the Ngrok-Error-Code header of ERR_NGROK_3200 and the returned HTML body, we know that the URL our workflow called does not exist.